Notícias
Usando os preceitos do Big Data na Gestão do Conhecimento do Serpro
TemaTec 232


Márcio Assis é bacharel em Ciência da Computação pela Universidade Federal do Paraná (UFPR), mestre em Informática na mesma instituição e doutorando em Computação em Nuvem na Universidade Estadual de Campinas (Unicamp). Desde novembro de 2010 é analista de Redes no Serpro, atualmente lotado na Regional Curitiba.
O conhecimento é o bem mais importante de uma instituição e é inerente aos indivíduos (CMMI, 2000). Por muito tempo, os modelos de administração das instituições de Tecnologia da Informação e Comunicação não consideravam essa propriedade. Nesse cenário, cada indivíduo tornava-se uma ilha de conhecimento e sua passagem não agregava nada à instituição que perdia em custos e vantagens em relação à concorrência.
Em meados dos anos 90, a gestão do conhecimento surgiu como parte da administração (SVEIBY, 1998). Esse novo paradigma teve como objetivo incorporar definitivamente nas instituições o conhecimento dos indivíduos. Entre os benefícios diretos da gestão do conhecimento nas instituições, estão o aumento da eficácia e da eficiência na identificação das fontes de informações dentro do ambiente e tomada de decisões acertadas pela melhor estratégia a ser adotada em relação aos seus clientes. Contudo, determinadas ações da gestão do conhecimento desencadearam um fenômeno: pulverização dos dados do conhecimento dos indivíduos. Dessa forma, pensar “fora da caixinha” pode auxiliar o desenvolvimento de soluções para o problema descrito e, consequentemente, a gestão do conhecimento.
Os preceitos do Big Data
O Big Data é uma ciência voltada para a análise de diversas fontes de dados, que possibilita a geração de correlações sobre um objeto de interesse baseadas em um espaço amostral e temporal. O conjunto de dados Big Data pode ser caracterizado como um modelo multi-V (ASSUNÇÃO et. al, 2014), sendo que a combinação mais popular (ZIKOPOULOS, et. al, 2012) é formada por três “Vs”:
-
Volume: compreende a quantidade avassaladora de dados digitais que são produzidos a partir da interação humana com os serviços digitais. O Big Data descreve algumas ações que contribuem para melhorar a análise dessa quantidade de dados, tais como eliminar fontes não pertinentes (ex.: monitoramento), definir um escopo de análise e eliminar fontes redundantes.
-
Velocidade: define a taxa de produção e consumo dos dados. O desafio nesse cenário vai além da preocupação com a transferência de dados, pois considera também mecanismos para administrar a taxa de produção. Das soluções para mitigar esses desafios estão: a implementação de sistemas de caches; novas arquiteturas que realizam o balanço entre a latência gerada nas requisições com os processos de análise e decisão.
-
Variedade: sensores, transações em comércio eletrônico e redes sociais são algumas das atividades que geram dados. Somada às múltiplas fontes está a diversidade das estruturas de representações desses dados. Utilização de representações universais como o XML e/ou implementação de ferramentas de gerência de metadados podem ser soluções para mitigar as dificuldades relacionadas à variedade.
Repositórios de dados
Quanto à pulverização, os dados de interesse são armazenados em repositórios, que podem estar localizados dentro do domínio do Serpro ou externos à instituição, sendo administrados e mantidos por instituições que atuam em outros segmentos (acadêmica, mercado de trabalho etc.). Os repositórios externos são pertinentes, pois alguns deles são bastante atualizados. Para compor a solução, então, foi considerado um conjunto de repositórios internos e externos ao Serpro. Os repositórios internos são: Sisgad, Anais do ConSerpro e HisAq. Já os repositórios externos de dados selecionados foram o ResearchGate (produção acadêmica) e o LinkedIn (perfil profissional).
Framework
O Framework para Gestão de Conhecimento (FGC) foi idealizado com o objetivo de utilizar os preceitos do Big Data na captação de dados de diversos repositórios internos ou externos ao Serpro para gerar informações pertinentes às tecnologias já prospectadas em outros projetos, assim como informações referentes às capacidades técnicas dos colaboradores, identificando aqueles que possuam conhecimento especializado para problemas de interesse. Tais informações serão então utilizadas principalmente para otimizar o processo de prospecção e desenvolvimento de soluções para novas demandas da empresa.
O FGC é composto por um conjunto de componentes (Figura 1, abaixo) responsáveis pela aquisição de dados de repositórios e pela geração de informações acerca desses dados.
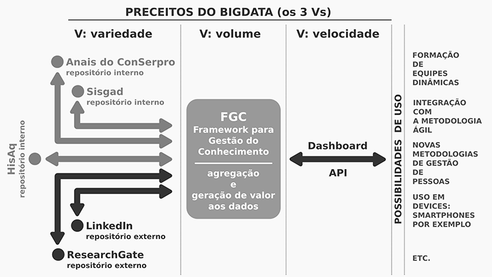
Figura 1: macrovisão do FGC. Destaque para as possibilidades de uso.
Arquitetura
O FGC (Figura 2, abaixo) é formado pelos componentes Coletor, Concentrador e Normalizador, que possuem responsabilidades específicas e interagem com os repositórios de dados internos e externos ao Serpro. Também é previsto uma interface de consulta por meio da implementação de um portal web e a disponibilização de uma API para a interação direta com a ferramenta.
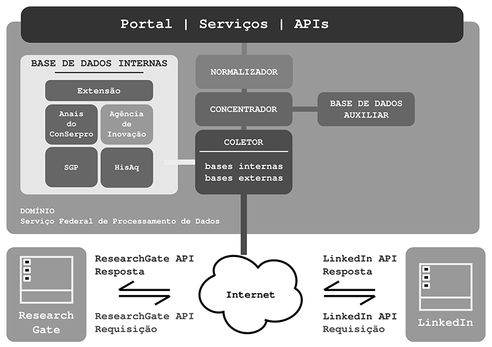
Figura 2: arquitetura do FGC
-
O Coletor: responsável pela comunicação e obtenção de dados dos repositórios suportados pelo FGC (dimensão variedade do Big Data). Este componente foi desenvolvido considerando uma arquitetura baseada em plugins onde é necessário um adaptador para cada repositório suportado, oferecendo ao mesmo tempo escalabilidade (inserção de novos repositórios sob demanda) e alcançabilidade (atende repositórios que não dispõem de APIs).
-
O Concentrador: intermedeia o processo de consultas dentro do FGC. Este componente preconiza a dimensão velocidade do Big Data. Para desempenhá-la o Concentrador realiza a filtragem de consultas recebidas do componente Normalizador e agrega as que sobraram em uma única requisição que então é enviada ao Coletor.
-
O Normalizador: incumbido de tratar as consultas, seja na emissão quanto na recepção do resultado. Tem uma função léxica dentro do FGC, preparando as consultas e formatando os resultados de um modo uniforme para que sejam interpretados corretamente pelas interfaces de apresentação e pelo componente Concentrador. Também permite a humanização do resultado gerado pelo FGC, permitindo a leitura desses resultados não apenas por profissionais da área tecnologia, mas sim por qualquer tipo de usuário.
-
Interfaces: são considerados um o portal de acesso web e uma API de interação.
Possibilidades de aplicabilidade
O FGC tem como seu principal nicho de atuação a melhora do processo de prospecção das demandas dentro do Serpro. Como é uma ferramenta independente de outros sistemas, ela pode ser utilizada de maneiras distintas. O FCG permite o rastreio e a obtenção de funcionários com capacitação em determinadas tecnologias ou que já trabalharam com ela. Esses, por sua vez, podem ser requisitados a prestarem consultoria interna, dispensando com isso possíveis aquisições de capacitações externas ao Serpro e, consequentemente, redução de custos e/ou aumento da eficiência na constituição de novas equipes.
Conclusões
O FGC de auxílio à gestão do conhecimento do Serpro pretende usar de forma unificada e automática um conjunto de repositórios internos e externos à instituição para aumentar a captação de dados referentes ao corpo funcional. Como demonstrado neste documento, a implementação e utilização do FGC é factível e agrega um dinamismo ao processo de prospecção e formação de equipes dentro do Serpro.
Somado a isso, o rastreio da capacidade registrada em repositórios externos à instituição aumenta a qualidade e a representação das informações obtidas. Por fim, a economia de custo que o Serpro pode obter com a diminuição de eventuais cursos de capacitação para atender as demandas, a contratação de consultoria externa, a formação mais ágil da equipe e a possibilidade de implementação de outras formas de trabalho torna atraente a utilização do FGC.
Referências
- CMMI. CMMI model components derived from CMMI – SE/SW. Carnegie Mellon University, 2000. (Version 1.0 Technical report CMU/SEI-00-TR24).
- SVEIBY, K. E. A nova riqueza das organizações. 4ª Edição. Campus, 1998. 260p.
- ASSUNÇÃO, M. D. et. al. Big Data computing and clouds: challenges, solutions, and future directions. The University of Melbourne, 2013. 44p. (Technical Report CLOUDS-TR-2013-1).
- ZIKOPOULOS, P. et. al. Understanding BigData: analytics for enterprise class hadoop and streaming data. 1ª Edição. McGraw-Hill Companies, Inc. 2012. 176p.
Este artigo foi baseado em trabalho premiado no ConSerpro 2015
 Autor:
Autor:
Márcio Roberto Miranda Assis é bacharel em Ciência da Computação pela Universidade Federal do Paraná (UFPR), mestre em Informática na mesma instituição e doutorando em Computação em Nuvem na Universidade Estadual de Campinas (Unicamp). Desde novembro de 2010 é analista de Redes no Serviço Federal de Processamento de Dados (Serpro), atualmente lotado na COGTI/CINGC/SICSI – Regional Curitiba/PR.


