Notícias
Análise de redes sociais para inferência de similaridade entre fornecedores de governo
TemaTec 233




Introdução
O Brasil está passando por uma crise de suas instituições. Escândalos corporativos envolvendo corrupção de agentes públicos são assuntos recorrentes, fortalecendo ainda mais a percepção pela população de que os processos de aquisição do governo estão dominados por associações entre fornecedores que agem sob má conduta econômica e fiscal.
Este trabalho propõe um método baseado em análise de redes complexas, ou como é mais conhecida, análise de redes sociais (SNA – Social Network Analysis) [1], para inferência de associações entre fornecedores de governo com base em seus padrões de venda, extrapolando para um modelo de classificação sensível à idoneidade dos fornecedores. Os dados sobre gastos de governo e idoneidade foram todos obtidos do Portal da Transparência da CGU [2].
A estrutura baseada em redes do modelo, bem como a relevância dos resultados experimentais, reforçam as hipóteses de que existem associações entre fornecedores e de que agentes públicos desempenham um papel importante na legalidade das transações financeiras. Ao mesmo tempo em que sistemas analíticos deste tipo são importantes para a sociedade no sentido de dar mais transparência pública, eles também se revelam como extremamente úteis para os órgãos de investigação e fiscalização no Brasil, pois apoiam a tomada de decisão no sentido de reduzir o espaço de busca por alvos e hipóteses mais prováveis de serem confirmadas.
Modelo de redes de fornecedores de governo
Um método baseado em SNA foi proposto para inferir grau de similaridade entre fornecedores a partir de suas afiliações no contexto de transações financeiras (gastos) envolvendo órgãos do governo federal. Afiliações são extraídas de transações classificadas como pagamento direto (de órgãos de governo para fornecedores) e cartões corporativos (de pessoas autorizadas para fornecedores). O modelo final produzido, isto é, a rede inferida de fornecedores, tem o intuito de produzir uma aproximação da rede real de fornecedores, com arestas ponderadas pela probabilidade de comportamento similar.
Este trabalho está particularmente interessado nas seções de gastos diretos e transferências financeiras. Gastos diretos podem ser de dois tipos: pagamentos de órgãos de governo para empresas; e Cartão de Pagamento do Governo Federal (CPGF). Em relação às transferências, estão sendo considerados apenas os dados de Cartão de Pagamentos da Defesa Civil (CPDC), que faz uso dos recursos federais repassados pelo Ministério da Integração Nacional no contexto de convênios com Estados e Municípios, visando o apoio às ações de socorro. Fornecedores inidôneos também estão disponíveis no portal, o que inclui o Cadastro de Empresas Inidôneas e Suspensas (Ceis) e Cadastro de Entidades Sem Fins Lucrativos Impedidas (Cepim). Os dados de gastos de governo permitem extrair as seguintes conexões:
-
Órgão de governo e fornecedor – conexão entre órgão de governo (afiliação) e fornecedor (afiliado) ponderada pela quantidade total de dinheiro repassado pelo órgão à empresa fornecedora ao longo de um período de tempo;
-
Indivíduo e fornecedor – conexão entre portador de CPGF ou CPDC (afiliação) e fornecedor (afiliado) ponderada pela quantidade total de dinheiro repassado pelo indivíduo à empresa fornecedora ao longo de um período de tempo.
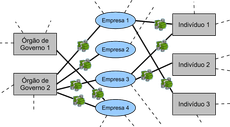
O grafo de afiliações entre os fornecedores produzido não contém conexões entre as empresas, conforme ilustrado pela Figura 1 (abaixo). A ideia é, a partir deste grafo, inferir um segundo grafo de conexões entre os fornecedores com arestas ponderadas pelo nível de similaridade entre eles. Essa similaridade é inferida a partir dos seus padrões de vendas, ou seja, a partir das afiliações e pesos das arestas neste primeiro grafo.
Figura 1. Grafo de afiliações de fornecedores
Um segundo grafo, o de associações entre fornecedores, é gerado, tomando-se como ponto de partida a hipótese de que a rede de similaridades entre fornecedores pode ser inferida a partir de suas afiliações compartilhadas e pesos das suas conexões, e que empresas verdadeiramente similares estão no mesmo componente conectado do grafo [1].
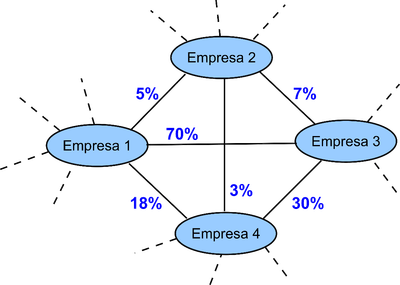
A similaridade entre um par de empresas a e b é obtido a partir de uma variação do coeficiente de similaridade de Jaccard [3]. A variação do coeficiente tradicional de Jaccard é necessário para contemplar os valores de ponderação das arestas. Isto significa estender o conceito de similaridade para incluir também o de similaridade entre arestas, ou seja, tornar a similaridade entre as arestas de dois fornecedores para uma mesma afiliação proporcional à similaridade entre os seus valores. A Figura 2 (ao lado) ilustra esta nova rede. Note que algumas conexões no grafo podem representar similaridades muito baixas. Dessa forma, estabeleceu-se um limiar mínimo de similaridade entre fornecedores para remoção de arestas com valores muito baixos.
Figura 2. Rede de associações entre fornecedores
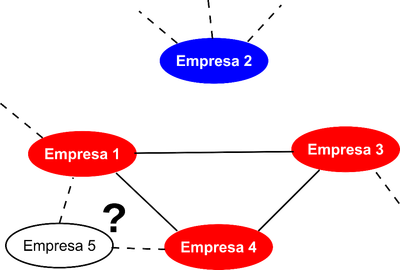
Após a formação da rede de associações entre as empresas, elas são rotuladas como idôneas ou inidôneas de acordo com o Ceis e Cepim. A Figura 3 (abaixo) ilustra essa rotulação, exibindo os fornecedores idôneos na cor azul e os inidôneos na cor vermelha. Ademais, a rede de associações entre empresas rotuladas como idôneas ou inidôneas serve de modelo de classificação para outros fornecedores ainda não vistos. A Figura 3 ilustra ainda um exemplo dessa classificação.
Experimentos e Resultados
Há empresas idôneas e inidôneas. A hipótese a ser testada pelos experimentos é a de que fornecedores idôneos se comportam de maneira mais similar entre si, assim como os inidôneos. Em termos dos grafos gerados e de acordo com a mencionada hipótese, clusters (componentes conectados) tendem a ser homogêneos em relação à presença de companhias idôneas e inidôneas. Os experimentos realizados consideram os seguintes dados:
Figura 3. Inferência probabilística sobre a idoneidade de novos fornecedores
-
Gastos diretos coletados de janeiro de 2011 a março de 2014;
-
Ceis de 30/7/2015;
-
Cepim de 30/7/2015;
-
Balanceamento de classes de idôneos e inidôneos;
-
Considerou-se apenas gastos diretos de 2011 a 2014 e bases atualizadas (julho/2015) do Ceis e Cepim;
-
Inclusão de procedimento de remoção de arestas com maiores valores de betweenness.
A Tabela 1 (abaixo) exibe o desempenho em classificação para diferentes valores de σ (limiar mínimo de similaridade). É interessante notar que a configuração com melhor desempenho é aquela com similaridade mínima de 10% entre os fornecedores. Exceto para σ=1.0, que se mostrou mais distante dos demais, o desempenho de classificação geral do modelo. Para ficar mais claro, um acerto em classificação de 89,06% significa conseguir distinguir aproximadamente nove em cada dez fornecedores como idôneos ou inidôneos, isso com base em seus padrões de vendas para órgãos de governo.
|
|
σ = 0,1 |
σ = 0,25 |
σ = 0,5 |
σ = 0,75 |
σ = 1,0 |
|
Classificação |
89,06% |
86,78% |
88,26% |
88,62% |
75% |
Tabela 1. Desempenho de classificação (idôneo/inidôneo) das redes de associações entre fornecedores para diferentes valores de σ.
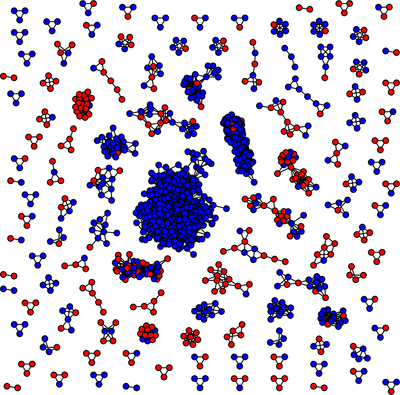 A Figura 4 (ao lado) exibe as redes de associações entre empresas idôneas (azuis) e inidôneas (vermelhas) para σ=0.01 e remoção de 40%.
A Figura 4 (ao lado) exibe as redes de associações entre empresas idôneas (azuis) e inidôneas (vermelhas) para σ=0.01 e remoção de 40%.
Conclusões
Os resultados apresentados mostram que os modelos apresentados geraram clusters que são discriminativos em relação à idoneidade das empresas, permitindo seu uso como modelo de classificação. Em todo os experimentos os resultados foram bastante aceitáveis (acertos de até 89%). O poder discriminativo dos clusters reforça a hipótese de que existem associações entre fornecedores, com potencial aprofundamento para detecção de cartéis.
Figura 4. Rede de empresas idôneas (azuis) e inidôneas (vermelhas) para σ=0.01.
Referências
[1] EASLEY, D.; KLEINBERG, J. Networks, Crowds, and Markets: Reasoning About a Highly Connected World. Cambridge University Press, 2010.
[2] CONTROLADORIA GERAL DA UNIÃO. Portal da Transparência, 2015. Agosto de 2015.
[3] JACCARD, P. Étude comparative de la distribution orale dans une portion des Alpes et des Jura. In: Bulletin de la Société Vaudoise des Sciences Naturelles, v. 37, 1901, pp. 547-579.
Este trabalho foi premiado no Congresso Serpro de Tecnologia e Gestão aplicadas a Serviços Públicos (ConSerpro) 2015, em segundo lugar no tema Relação Governo e Sociedade.
 Marcelo Pita
Marcelo Pita
Engenheiro da Computação e mestre em Engenharia da Computação pela Universidade de Pernambuco (UPE). Atualmente é doutorando em Ciência da Computação no Departamento de Ciência da Computação da Universidade Federal de Minas Gerais (UFMG) e trabalha na Regional Belo Horizonte do Serpro, na Coordenação de Informação e Inteligência para Governo. Tem interesse em machine learning e analytics.
 Gustavo da Gama Torres
Gustavo da Gama Torres
Analista de desenvolvimento do Serpro e professor adjunto III da Pontifícia Universidade Católica de Minas Gerais. É doutor em Ciência da Computação pela UFMG. Na academia, atua na área de Ciência da Computação, com ênfase em técnicas de computação e engenharia de software. Na administração pública, atua no estabelecimento da pesquisa de computação aplicada em governo eletrônico.
 Sérgio Mariano Dias
Sérgio Mariano Dias
Analista de desenvolvimento do Serpro e doutorando em Ciência da Computação pela Universidade Federal de Minas Gerais. É mestre em Ciência da Computação pela UFMG (2008-2010) e bacharel em Ciência da Computação pela PUC-Minas (2003-2007). Possui experiência nos seguintes temas: análise de sistemas, análise formal de conceitos, aprendizado de máquina e ciência de dados.


