Notícias
Open Analysis
Tematec 237





Introdução
O conceito de dados abertos está relacionado à publicação e à disseminação de dados governamentais na internet. A disponibilização de dados governamentais abertos pode permitir que as informações contidas nesses dados venham a ser manipuladas de forma a gerar valor para o governo e a sociedade. A disponibilização de dados governamentais abertos objetiva possibilitar que a sociedade facilmente venha a encontrar, acessar, entender e utilizar os dados públicos segundo seus interesses e conveniências. Os dados governamentais devem ser disponibilizados, indexados e apresentados em um formato compreensível por máquina (Diniz, 2010). O Serviço Federal de Processamento de Dados (Serpro), empresa pública vinculada ao Ministério da Fazenda, é uma das empresas que promovem a disponibilização e uso de dados abertos no Brasil.
Todo governo possui uma quantidade considerável de informações para uso em suas operações internas e prestação de serviços. Uma das formas mais eficientes de analisar uma grande quantidade de dados é o uso de recursos de mineração de dados. A prática de mineração de dados pode apresentar informações sobre os dados analisados e, posteriormente, a descoberta de novos conhecimentos, prática muito útil no auxílio ao processo decisório (Diniz, 2010) (Baker et al., 2011).
O presente estudo propõe uma solução, denominada OpenAnalysis, que permitirá a análise de dados governamentais utilizando software livre. A solução propõe extrair padrões e respostas a partir de dados a serem definidos pelo governo.
1. Prova de Conceito
Apesar de o governo brasileiro disponibilizar diversos dados abertos em diversos portais institucionais (http://dados.gov.br/), a falta de metadados adequados, e o uso de formatos proprietários dificultam o uso desses dados em ferramentas de análise de dados. Dessa forma, a prova de conceito das técnicas apresentadas utilizou uma base de dados com informações de todos os crimes na cidade de Chicago desde 2001. Um dos objetivos da proposta é que o Serpro forneça os dados em formato adequado à adoção da solução. A base de dados foi escolhida pelo volume dos dados, acesso, integridade das informações armazenadas e relevância do assunto segurança pública. O objetivo da prova de conceito é demonstrar que é possível aplicar as técnicas apresentadas em dados governamentais agregando valor ao governo brasileiro e à sociedade. Os questionamentos a serem respondidos pela prova de conceito são:
Tabela 1: Hipóteses a serem respondidas pela prova de conceito
| Hipóteses | |
|---|---|
| H1 | As ferramentas utilizadas pela solução OpenAnalysis podem identificar padrões e respostas para problemas de segurança a partir de dados abertos disponibilizados pelo governo? |
| H2 | Os padrões encontrados pelas ferramentas podem auxiliar o governo brasileiro na melhoria da prestação de seus serviços junto a sociedade? |
A prova de conceito foi organizada em três experimentos e uma análise final. Os experimentos utilizaram as ferramentas Weka, Gephi e RStudio, e os algoritmos de agrupamento K-Means e DB-Scan.
1.1 Experimentos aplicados na prova de conceito
Os experimentos utilizaram a base de crimes disponibilizada pela prefeitura de Chicago (no endereço https://data.cityofchicago.org/Public-Safety/Crimes-2001-to-present/ijzp-q8t2). A base foi segmentada por ano, devido ao fato de os recursos de máquina disponíves serem insuficientes para processar todo o conjunto de dados. A máquina utilizada para os experimentos foi um notebook de 8 Gb de memória e 150 Gb de disco. O experimento utilizou os crimes ocorridos em Chicago, no intervalo de 1º de janeiro até o dia 14 de março de 2005.
1.1.1 Primeiro experimento
O primeiro experimento utilizou o algoritmo K-Means e a ferramenta Weka. O algoritmo foi configurado de forma a gerar dois agrupamentos (clusters). O primeiro cluster agrupou 84% das instâncias e o segundo cluster reuniu 16% das instâncias. A partir da análise dos agrupamentos (Tabela 2), pode-se concluir que no período estudado:
• a maioria dos crimes que acontecem em Chicago diz respeito a roubos de menos de 500 dólares (Tabela 2 - Cluster 1);
• a maioria dos roubos acontece na rua (Tabela 2 - Cluster 1);
• na maioria dos roubos não ocorre a prisão do acusado no momento do crime (Tabela 2 - Cluster 1);
• o segundo maior crime em incidência é o de agressão (Tabela 2 - Cluster 2);
• a maioria das agressões ocorre em apartamentos (Tabela 2 - Cluster 2);
• na maioria das agressões ocorre a prisão do acusado (Tabela 2 - Cluster 2);
• a maioria das agressões é do tipo agressão doméstica simples;
• os dois endereços em que ocorrem mais crimes são "001XX N STATE ST"e "010XX N LARAMIE AVE" (Tabela 2 - Cluster 1 e Cluster 2).
• apesar de o crime mais comum ser roubo, danos criminais a veículos ocorrem bastante nas ruas de Chicago. Geralmente, o criminoso não é preso em flagrante;
• a polícia de Chicago necessita orientar varejistas quanto aos roubos frequentes em lojas de departamento, em especial os proprietários de lojas no endereço "001XX N STATE ST";
• uma grande quantidade de roubos em residências e casos de posse de maconha ocorrem no mesmo endereço "0000X W TERMINAL ST". Na maioria dos casos de posse de maconha na cidade de Chicago, a droga pesa menos de 30 gramas e geralmente acontece a prisão do acusado; e
• Os seguintes endereços merecem atenção especial do Departamento de Polícia:"079XX S ABASH AVE", "010XX N LARAMIE AVE", "035XX S RHODES AVE", "001XX N STATE ST", "0000X W TERMINAL ST", "123XX S NORMAL AVE", "008XX N MICHIGAN AVE", "014XX W LAKE ST"e "093XX S LAFLIN ST".
Tabela 2: Clusters obtidos pelo algoritmo K-Means com valor de k=2
| Agrupamentos Obtidos | ||
|---|---|---|
| Atributos | Cluster 1 | Cluster 2 |
| Endereço | 001XX N STATE ST | 010XX N LARAMIE AVE |
| Tipo | ROUBO | AGRESSÃO |
| Descrição | MENOS DE US$ 500 | AGRESSÃO DOMÉSTICA SIMPLES |
| Localização | RUA | APARTAMENTO |
| Prisão | NÃO | SIM |
1.1.2 Segundo experimento
O segundo experimento utilizou a técnica de análise de redes de informação e a ferramenta Gephi para complementar os padrões encontrados no primeiro experimento e descobrir novos padrões relacionados a crimes em ruas e partamentos de Chicago. A primeira atividade do experimento foi aplicar uma distribuição circular a uma rede extraída com os atributos de localidade e tipo de crime.
A Figura 1 apresenta o gráfico de redes com distribuição circular dos crimes ocorridos em Chicago. O tamanho dos nós foi configurado a partir do atributo grau de saída (degree). A espessura da aresta de conexão foi configurada pelo número de conexões entre os nós. Os nós que representam crimes do tipo Roubo (THEFT) (Figura 1-1) e Dano Criminal (CRIMINAL DAMAGE) (Figura 1-2) são hubs com muitos relacionamentos de saída. O nó que representa Rua (STREET) é um hub com elevado grau de in-degree (Figura 1-3).
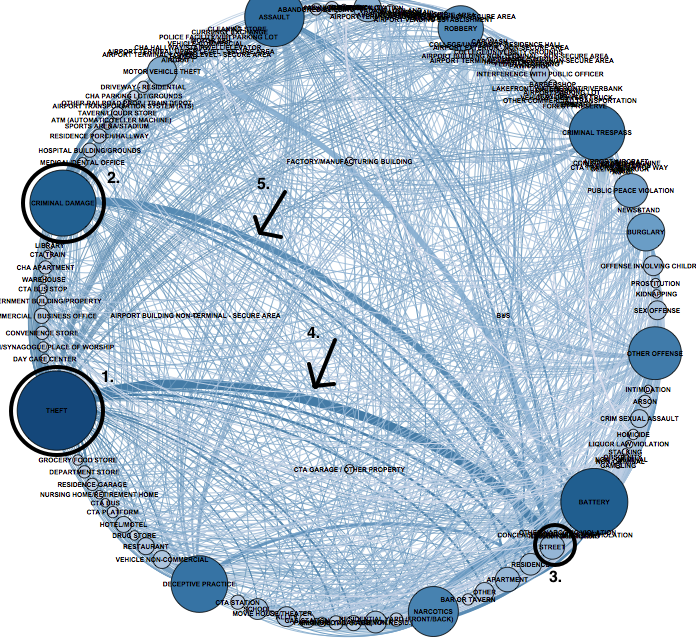
Figura 1: Gráfico de rede da base de crimes de Chicago utilizando o Layout Dual Circle
A Figura 1 apresenta um elevado número de conexões (espessura da aresta) entre os nós de valores Roubo e Danos Criminal com o nó de valor Rua (Figura 1-4 e 5). Pode-se concluir que:
• o crime que mais acontece em Chicago é o do tipo Roubo (nó de maior tamanho);
• muitos dos roubos e danos criminais de Chicago acontecem nas ruas (elevado número de conexões entre e os nós Roubo e Rua);
• ocorre um elevado número de agressões e assaltos em Chicago;
• um número menor de crimes é do tipo Prostituição e Ofensa Sexual.
A segunda atividade do experimento utilizou uma distribuição baseada em força e filtros do tipo Ego Network. O filtro Ego Network tem como principal função a seleção de um nó como hub central do gráfico. De forma a exemplificar o uso da técnica, o filtro foi aplicado para os nós Homicídio, Rua e Apartamento. A Figura 2 apresenta rede gerada utilizando o Ego Network para o nó Homicídio e com espessura das arestas calculadas a partir do atributo in-degree. A
rede utiliza como recurso apresentar o rótulo do nó proporcional ao seu valor de degree.
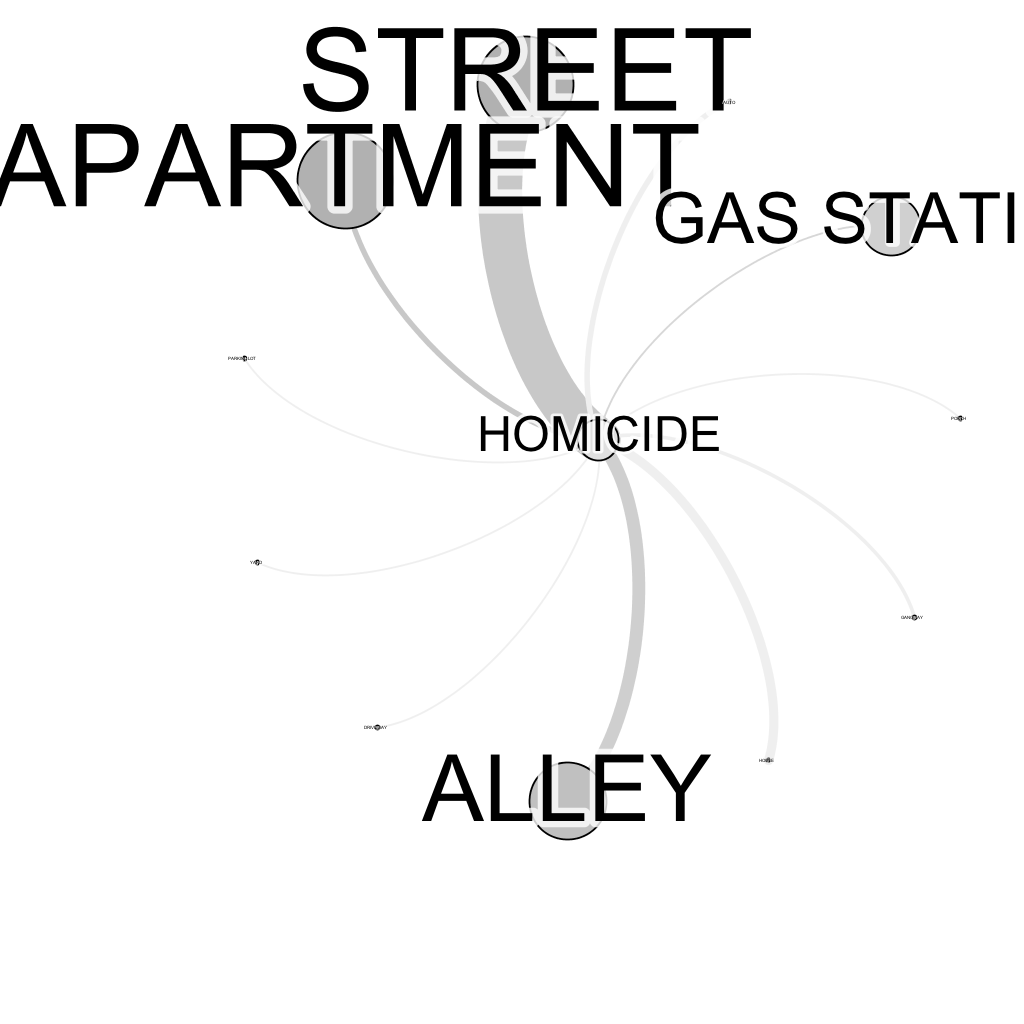
Figura 2: Diagrama com distribuição baseada em força e filtro Ego Network- Homicídios
Analisando a Figura 2 pode se concluir que:
• acontecem muitos crimes nas ruas de Chicago;
• grande parte dos homicídios em Chicago acontece nas ruas (STREET) e ruelas (ALLEY) ;
• alguns homicídios acontecem em apartamentos (APARTMENT) e postos de gasolina (GAS STATION).
A figura 3 apresenta uma rede criada com distribuição baseada em força e Ego Network para o nó Rua (STREET). A partir dos dados apresentados na Figura 3 pode se deduzir que:
• acontecem muitos roubos na rua de Chicago (Figura 3-1), sendo grande parte deles nas ruas (Figura 3-2);
• apesar de ocorrer muitos danos criminais em Chicago (Figura 3-4), ocorrem mais casos de crime de Narcóticos (Figura 3-3) nas ruas (Figura 3-6);
• ocorrem mais roubos a automóveis (Figura 3-8 e 9) do que assaltos (Figura 3-10 e 11) nas ruas de Chicago; e
• o número de crimes de prostituição nas ruas de Chicago é bem menor que os outros tipos de crime apresentados no gráfico (Figura 3-12).
A Figura 4 foi gerada utilizando-se o filtro Ego Network para o nó de rótulo apartamento (APARTMENT). A partir da figura pode-se deduzir que os crimes do tipo Agressão são os que mais ocorrem em apartamentos (Figura 4-1 e 2). Crimes do tipo Roubo e Dano Criminal também são frequentes nos apartamentos de Chicago (Figura 4-3,4,5 e 6). Sequestros (KID NAPPING) são crimes de menos incidência em apartamentos (Figura 4-7).
1.1.3 Terceiro experimento
O terceiro experimento utilizou a ferramenta R Studio e o algoritmo DB-Scan e recursos de mineração de texto. O algoritmo DB-Scan foi configurado para encontrar agrupamentos com densidade de 20 registros e Eps com valor 10.
A partir da execução do algoritmo, foram obtidos 30 clusters. A Figura 5 apresenta gráfico que mostra os 30 clusters obtidos com a execução do algoritmo DB-Scan. O eixo x do gráfico apresenta os tipos de crime e o eixo y indica as localidades. A partir do gráfico, pode-se perceber que crimes do tipo Roubo (figura 5-R) praticamente ocorrem em todos os tipos de localidade desde apartamentos a ruas.
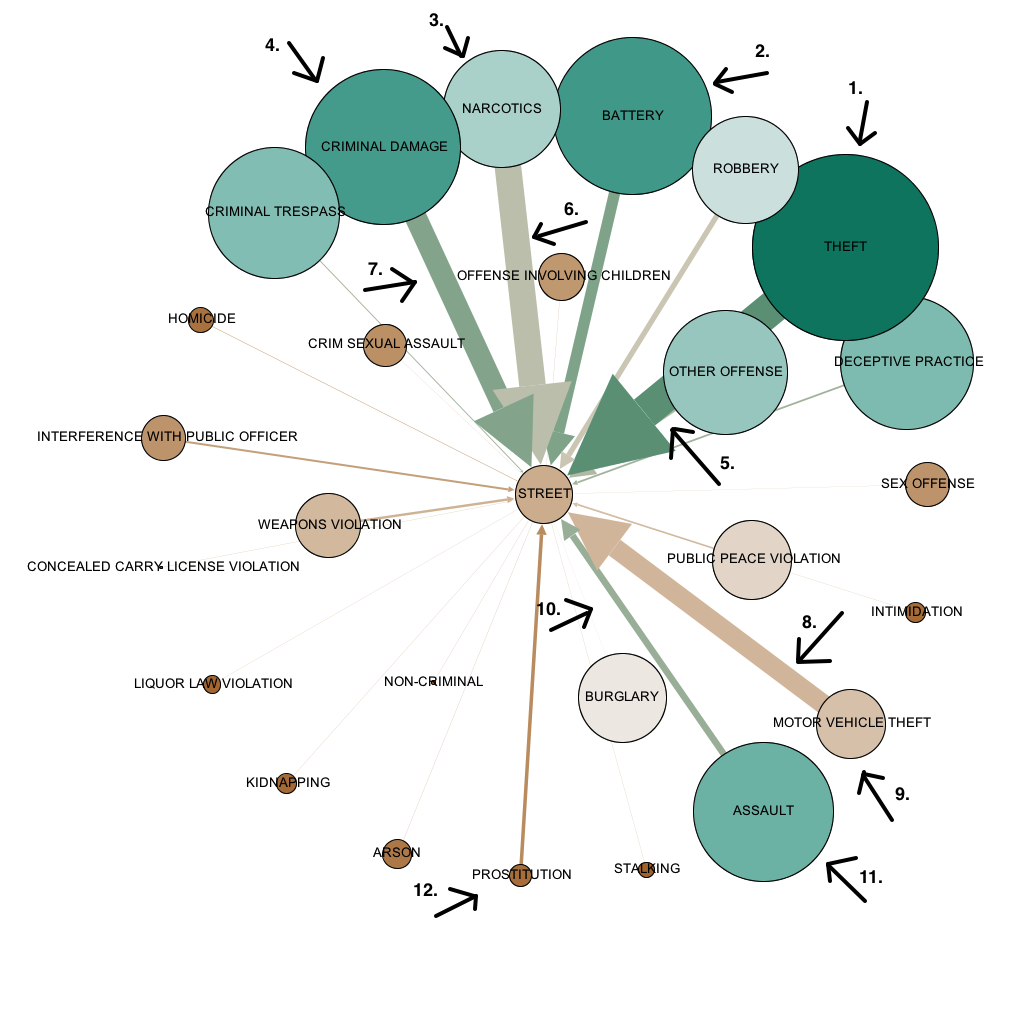
Figura 3: Gráfico de rede obtido no segundo que mostra os 30 clusters obtidos com a execução do algoritmo DB-Scan.
As principais diferenças entre o DB-Scan e o K-Means é que o DB-Scan é o número de clusters encontrados (o DB-Scan não possui um parâmetro com k número de clusters) e que o DB-Scan pode descobrir clusters de menores tamanhos, desde que o critério de densidade seja atendido. A aplicação do DB-Scan na base de crimes de Chicago permitiu encontrar um cluster associado ao crime de prostituição em dois endereços "0000X S KENTON AVE"e "0000X S KILBOURN AVE". Esse tipo de cluster dificilmente seria encontrado no K-Means com valor de k<10, pois trata-se de um cluster com poucos registros. A Tabela 3 apresenta os registros encontrados neste agrupamento.
A última atividade do terceiro experimento consistiu em usar um recurso de mineração de texto disponível na linguagem R. O procedimento consistiu em separar e contar as ocorrências das descrições e dos endereços onde aconteceram crimes e apresentar um gráfico do tipo nuvem com as palavras mais citadas. A Figura 6 apresenta gráfico de nuvem a partir de todas as palavras nas descrições de crimes na base de Chicago. As palavras de maior tamanho no gráfico são descrições de crimes com mais incidência. A partir da análise da Figura pode-se observar que: grande parte dos crimes de Chicago envolve veículos (TO VEHICLE), propriedades (TO PROPERTY) e valores acima de 500 dólares (OVER $500); diversos crimes financeiros, como roubo de identidade com mais de 300 dólares (FINANCIAL IDENTITY THEFT OVER $300); acontecem muitas ameaças por telefone em Chicago (TELEPHONE THREAT); crimes de violação de condicional (PAROLE VIOLATION) e assédio por meio eletrônico merecem atenção especial (HARASSMENT BY ELETRONIC MEANS).
Tabela 3: Cluster encontrado a partir do algoritmo DB-Scan
| Block | Primary Type | Location Description | |
|---|---|---|---|
| 4149 | 0000X S KENTON AVE | PROSTITUTION | STREET |
| 7508 | 0000X S KENTON AVE | PROSTITUTION | STREET |
| 11142 | 0000X S KENTON AVE | PROSTITUTION | STREET |
| 11843 | 0000X S KILBOURN AVE | PROSTITUTION | STREET |
| 15345 | 0000X S KILBOURN AVE | PROSTITUTION | STREET |
| 25056 | 0000X S KENTON AVE | PROSTITUTION | STREET |
| 25245 | 0000X S KILBOURN AVE | PROSTITUTION | STREET |
| 28926 | 0000X S KENTON AVE | PROSTITUTION | STREET |
| 35520 | 0000X S KILBOURN AVE | PROSTITUTION | STREET |
| 32524 | 0000X S KENTON AVE | PROSTITUTION | STREET |
| 33119 | 0000X S KILLPATRICK AVE | PROSTITUTION | STREET |
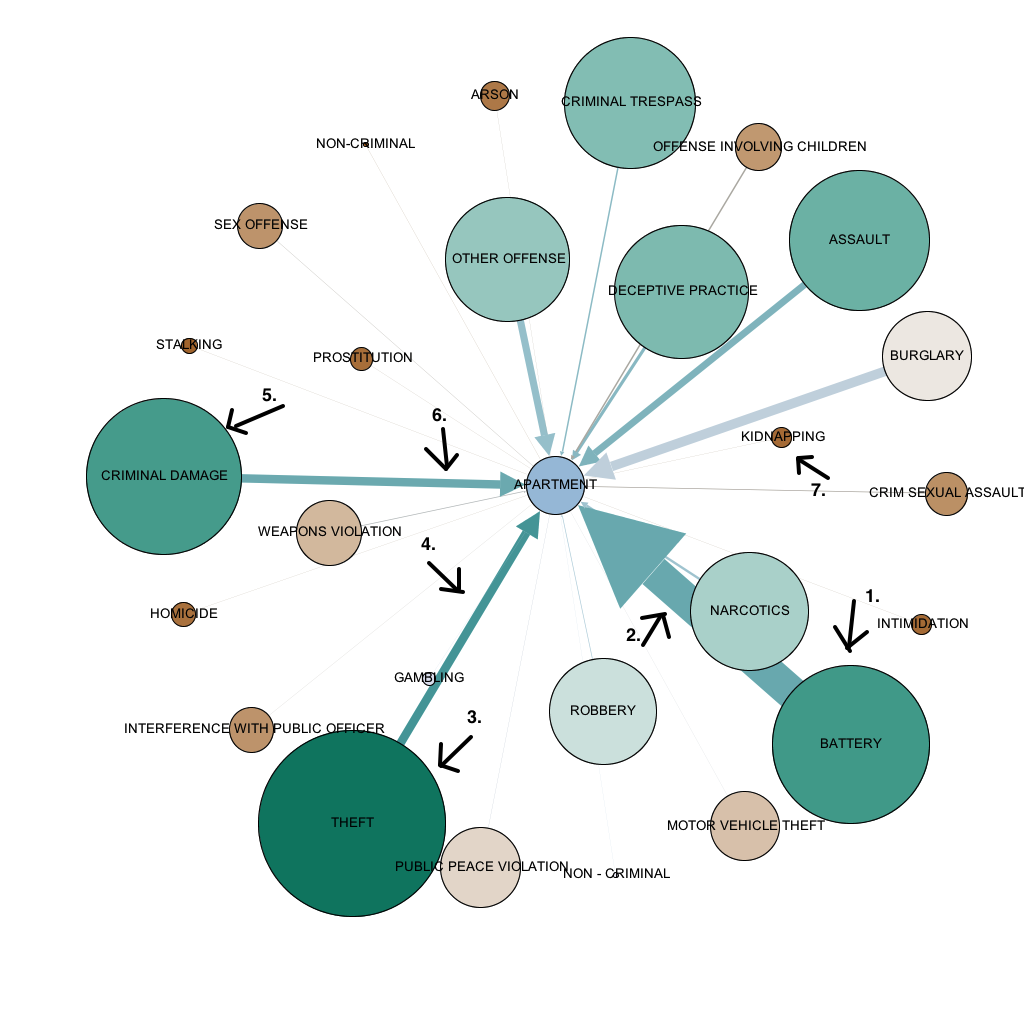
Figura 4: Gráfico de rede obtido no segundo experimento com Filtro Ego Network e parâmetro de profundidade de valor 1- Apartamento
A Figura 7 apresenta gráfico de nuvem com os nomes dos endereços onde aconteceram alguns tipos de crime. A partir do gráfico, pode-se deduzir que nos endereços "001XX N STATE ST", "0000X W TERMINAL ST" e "008XX N MICHIGAN AVE" ocorrem mais crimes em Chicago.
Os três experimentos conseguiram apresentar diversos padrões que podem servir de insumo para as autoridades públicas atuarem de forma mais eficaz e eficiente. A partir do experimento, descobriu-se que a maior parte dos crimes
em Chicago é de roubos de menos de 500 dólares e agressões domésticas. A maioria dos roubos acontece na rua, e não ocorre a prisão dos acusados, enquanto nas agressões geralmente se dá a prisão em flagrante. A polícia de Chicago deve orientar as lojas do endereço "001XX N STATE ST" quanto aos frequentes roubos, e talvez a instalação de câmeras no local seja uma boa prática. Políticas de prevenção ao uso de drogas devem ser realizadas no endereço "0000X W TERMINAL ST".
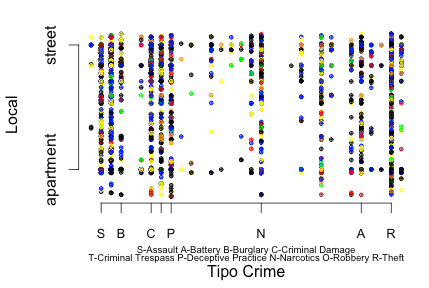
Figura 5: Gráfico de Plot com os clusters da base de Chicago utilizando o algoritmo DB-Scan
Campanhas contra a prostituição devem ser realizadas nos endereços "0000X S KENTON AVE" e "0000X S KILBOURN AVE". Crimes de violação de condicional e assédio por meio eletrônico merecem atenção especial.
Merecem atenção especial do Departamento de Polícia os seguintes endereços:"001XX N STATE ST", "0000X W TERMINAL ST", "008XX N MICHIGAN AVE", "079XX S ABASH AVE", "010XX N LARAMIE AVE","035XX S RHODES AVE", "123XX S NORMAL AVE", "008XX N MICHIGAN AVE", "014XX W LAKE ST"e "093XX S LAFLIN ST".

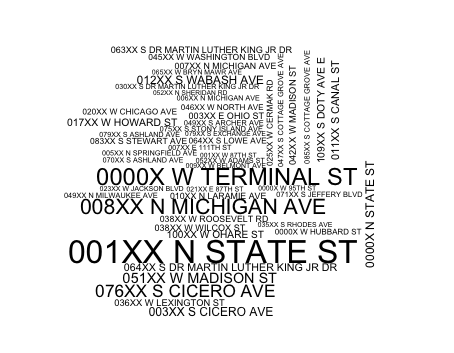
Fig. 6: Nuvem de palavras obtidas a partir das descrições de crimes Fig. 7: Nuvem de palavras obtidas a partir dos endereços da base
2. Conclusão
O presente estudo apresentou uma solução de uso integrado de várias ferramentas de análise de dados. A Prova de conceito foi realizada em três experimentos. A proposta inicial da prova de conceito era utilizar uma base de dados do governo brasileiro. No entanto, apesar de diversas bases estarem disponíveis no portal dados.gov.br, as bases presentadas ainda necessitam de recursos como metadados e dicionários de dados para correta aplicação das técnicas apresentadas no presente estudo. Dessa forma, foi utilizada uma base disponibilizada pela prefeitura de Chicago (no endereço https://data.cityofchicago.org/Public-Safety/ Crimes-2001-to-present/ijzp-q8t2) e disponível para uso e consultas públicas.
Os três experimentos conseguiram apresentar diversos padrões que podem servir de insumo para as autoridades públicas atuarem de forma mais eficaz e eficiente, fornecendo, inclusive, as principais regiões onde os departamentos de Polícia poderiam atuar.
As possibilidades de uso das técnicas apresentadas neste estudo possuem um enorme potencial, desde o combate a fraude e corrupção no país a um melhor direcionamento das políticas de segurança pública. O Serpro pode fazer parceria com a Dataprev, de forma a realizar análise nas bases de dados previdenciários e auxiliar o Ministério da Saúde no controle de endemias.
A solução possibilita ainda uma maior atuação do Serpro junto aos entes públicos, e tem um enorme potencial de arrecadação financeira, já que o serviço pode ser cobrado por acesso à informação ou por cada análise em particular.
Dentre as possibilidades de melhoria da presente solução, pode-se destacar:
I teste das técnicas e ferramentas em uma base de tamanho igual ou superir a 1 Terabyte;
II utilização de algoritmos estatísticos para agrupamento de dados;
III desenvolver interface gráfica para análise dos agrupamentos por analistas de dados; e
IV uso das técnicas de distribuição por geolocalização com a ferramenta Gephi.
Referências:
Baker, R., S. Isotani, and A. Carvalho (2011). Mineração de Dados Educacionais: Oportunidades para o Brasil. Revista Brasileira de Informática na Educação 19 (02), 03.
Diniz, V. (2010). Como Conseguir Dados Governamentais Abertos. III Congresso Consad de Gestão Pública.
 Francisco Nauber Bernardo Gois
Francisco Nauber Bernardo Gois
É doutorando pela Universidade de Fortaleza, possui Mestrado em Informática Aplicada pela UNIFOR e Especialização em Desenvolvimento WEB pela Universidade Federal do Ceará. Atualmente é analista desenvolvimento do Serviço Federal de Processamento de Dados. Tem experiência na área de Ciência da Computação, com ênfase em Search Based Tests e Aprendizado de Máquina.


